Historical Load and Pipeline Concurrency
Once the data pipelines have been setup, they will continue to run as scheduled, fetching fresh source data with each run. There may also be a requirement for historical data, which means additional pipeline parameters and executions. DataStori maintains data integrity through all stages and modes of the data load process.
Historical Load
In addition to the regular refresh of ongoing transaction data, users may need historical data in the data warehouse for several reasons including:
- Historical / trend analysis
- Maintaining the health and quality of the data warehouse
- Back-dated transaction data being added, modified or deleted in the source
A historical load is only applicable for incremental data feeds.
To run a historical load, go to the Integrations tab and select your integration tab. In the Datasets tab, click on the ellipsis and select 'Run Historical Load'.
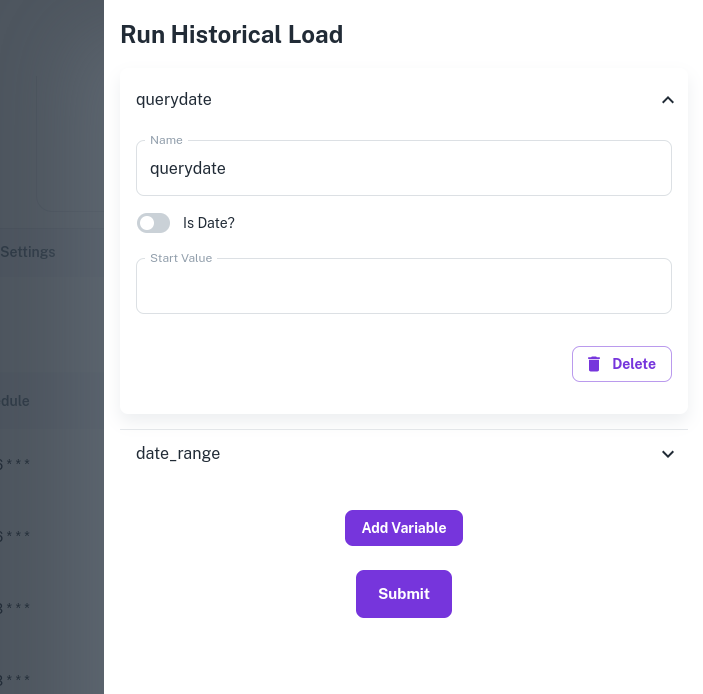
You will see the drawer populated with the Pipeline Variables. As an example, we will run a historical load using the querydate variable, with data to be loaded in batches to effectively manage data volume. In the Run Historical Load menu:
- Select the variable
- Mark it as a date variable
- Define the start_value, end_value, skip time unit = 1, and time unit as day
- Select the time format
This will generate a date for each of the days between start_value and end_value.
Examples
Backload on a single date variable: query_date
- Enter start_value as 01/01/2021, end_value as 31/12/2021, skip_time_unit = 1, time unit = DAY. This will generate 365 dates - 01/01/2021, 02/01/2021, 03/01/2021, ..., 31/12/2021.
Upon clicking on 'Submit', 365 pipeline runs will be submitted, one for each day of 2021.
- Enter start_value as 01/01/2021, end_value as 31/12/2021, skip_time_unit = 1, time unit = MONTH. This will result in 12 pipeline runs being submitted, with each having a start of the month value - 01/01/2021, 01/02/2021, 01/03/2021, ..., 01/12/2021.
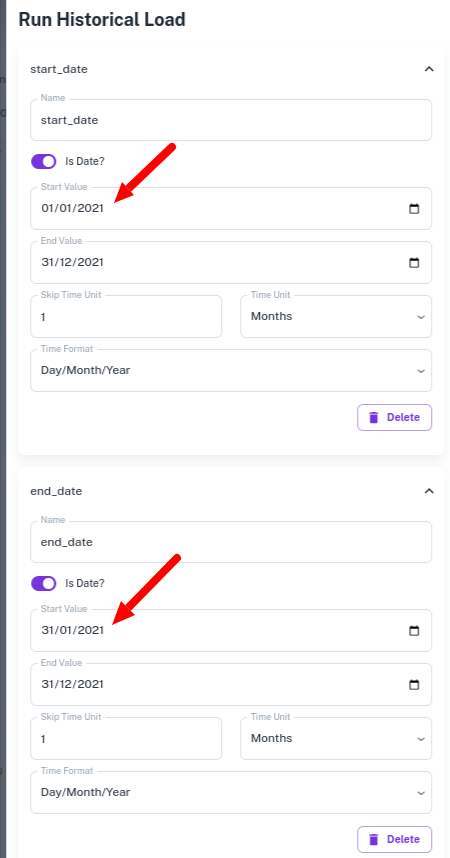
- Backload on a date range: Let's assume we have two pipeline variables (start_date, end_date), and the API call passes a date range. To run the historical load, we want to submit 12 pipeline runs with the following combinations:
{ "start_date": 01/01/2021, "end_date": 31/01/2021},
{ "start_date": 01/02/2021, "end_date": 28/02/2021},
{ "start_date": 01/03/2021, "end_date": 31/03/2021},
...
{ "start_date": 01/12/2021, "end_date": 31/12/2021}
To generate these combinations, the settings are as shown below.
Additional parameters: To provide additional parameters, e.g., fetch only active records during a historical load:
Add a pipeline variable: is_active = true
Under Historical load, keep the is_date flag off and provide a static value is_active = true, this is how the combinations will read:
{ "start_date": 01/01/2021, "end_date": 31/01/2021, "is_active": true},
{ "start_date": 01/02/2021, "end_date": 28/02/2021, "is_active": true},
{ "start_date": 01/03/2021, "end_date": 31/03/2021, "is_active": true},
....
{ "start_date": 01/12/2021, "end_date": 31/12/2021, "is_active": true}
- Historical data load is a resource and time intensive activity.
- You can load data for a given date range and do not need to run a complete sync of the source and the destination.
- Schema management and evolution will take place as the data is getting loaded.
Pipeline Concurrency
DataStori has a default pipeline concurrency = 1, i.e., at any given time only one instance of a pipeline (on a given dataset) is allowed to run. This is to avoid any race conditions in the data.
Among the concurrent pipeline runs submitted, only one will execute at a time, while the rest are queued up.
Queue ordering is not maintained, and any of the waiting pipeline runs can execute when the prior run completes. Collation and ordering of data takes place in the next step when the data load strategy is implemented on the ingested data.