4. Set up BusinessUnits Pipeline
BusinessUnits is a dimension table in ServiceTitan, whose API documentation is here.
Pipeline Configuration
Execution schedule: Run once daily at 6 AM Eastern Time.
Data load strategy: Fetch all records from the BusinessUnits API in every run and replace the existing records. This is a FULL REFRESH data load, and is followed when loading small and slowly changing tables.
Data schema management: Automatically include any new fields added to the API.
Data storage:
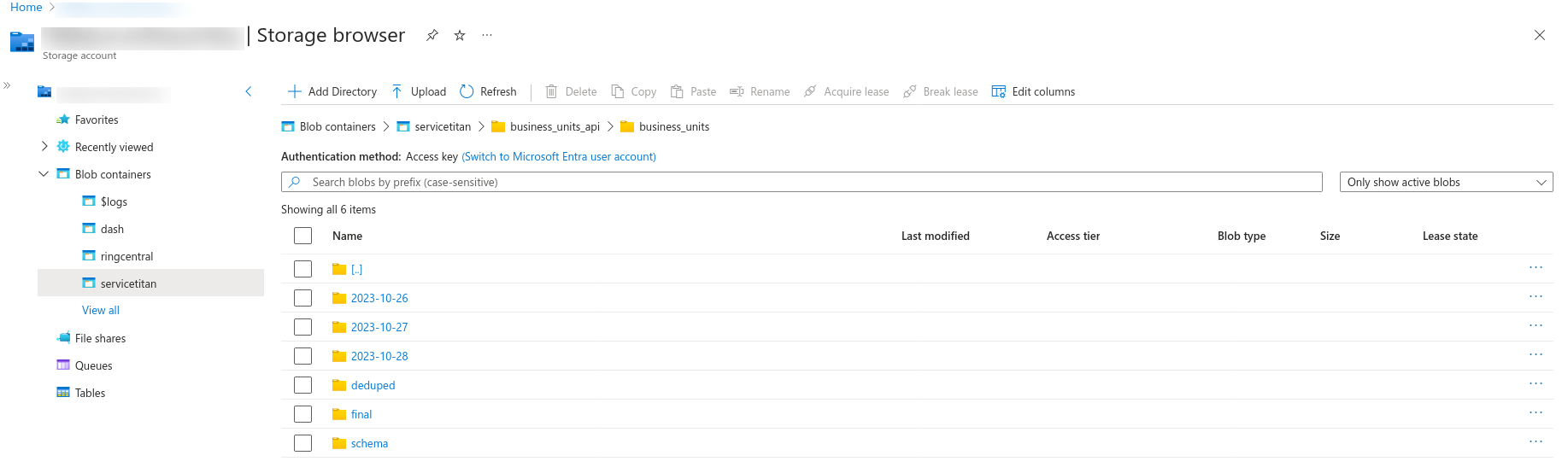
Azure Blob - In the Azure blob, create a Business Units folder, and inside it create a folder for each day's pipeline run.
Azure SQL - Create a 'servicetitan' schema, and inside it create a table called 'business_units' to receive data from the Azure Blob.
Pipeline Creation
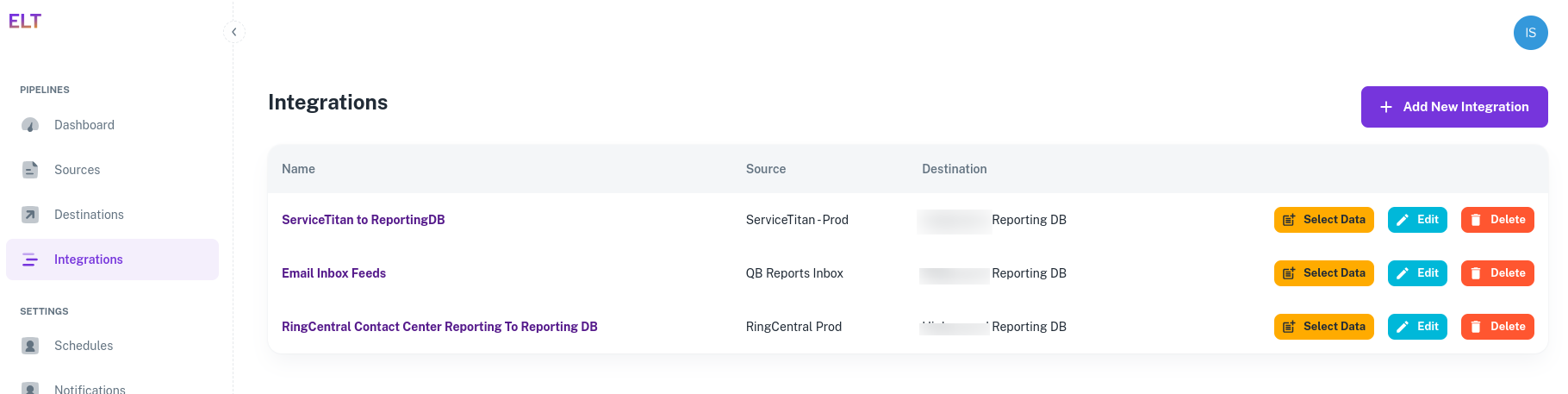
- In the Integrations Tab, click on 'Select Data' in the ServiceTitan to ReportingDB integration.
- Click on '+ Add New Dataset'.
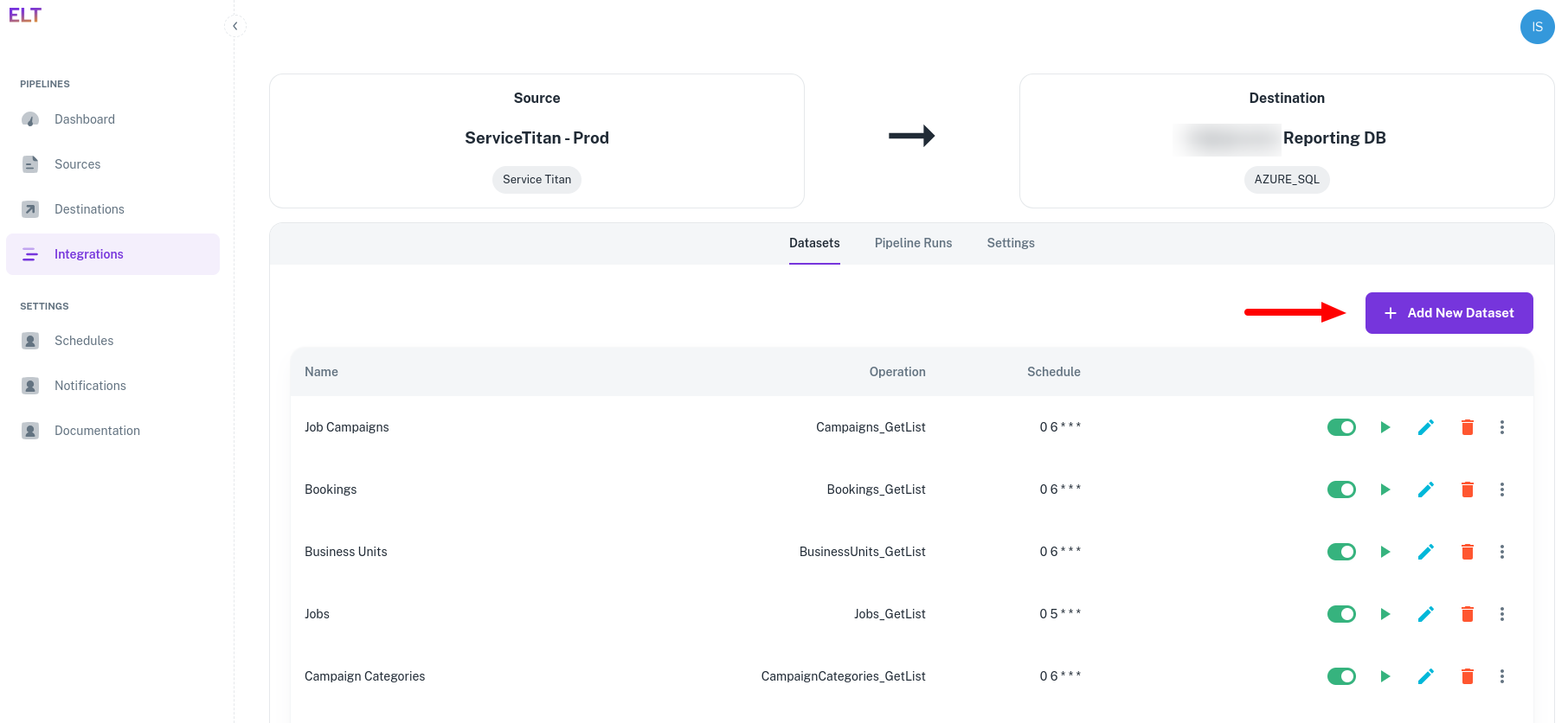
Creating the data pipeline is a three-step process.
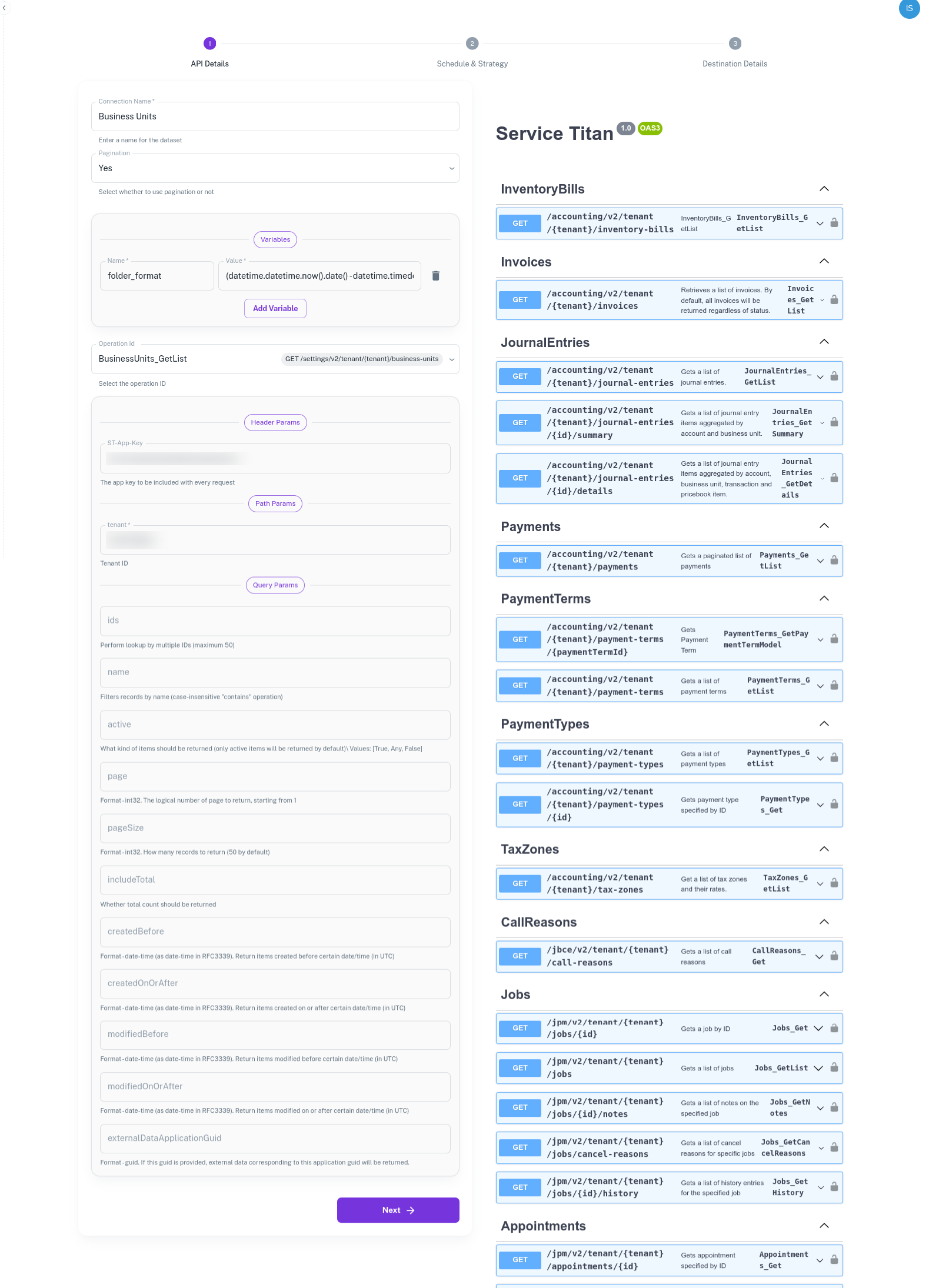
API Details: Specify the API from which data is to be fetched.
Connection/Pipeline Name - Name the dataset, e.g., BusinessUnits.
Pagination - DataStori automatically paginates over the APIs. If the API supports pagination, set it to Yes.
OperationId - Select the API from which to fetch the data. In this example, it is BusinessUnits_GetList.
Variables - These are dynamic inputs to the APIs. For example, date parameters or dynamic strings to define the folder format. Create a variable called 'folder_format' and provide the value
(datetime.datetime.now().date() - datetime.timedelta(days=1)).strftime('%Y-%m-%d')to create a date-wise folder in the blob.
Variables are python datetime functions that support a variety of input and output formats.
- API Parameters - API parameters are rendered based on the selected API. Populate the ST-App-Key and TenantID. You get these values on setting up API authentication. Leave the rest of the fields blank, except for required / mandatory variables.
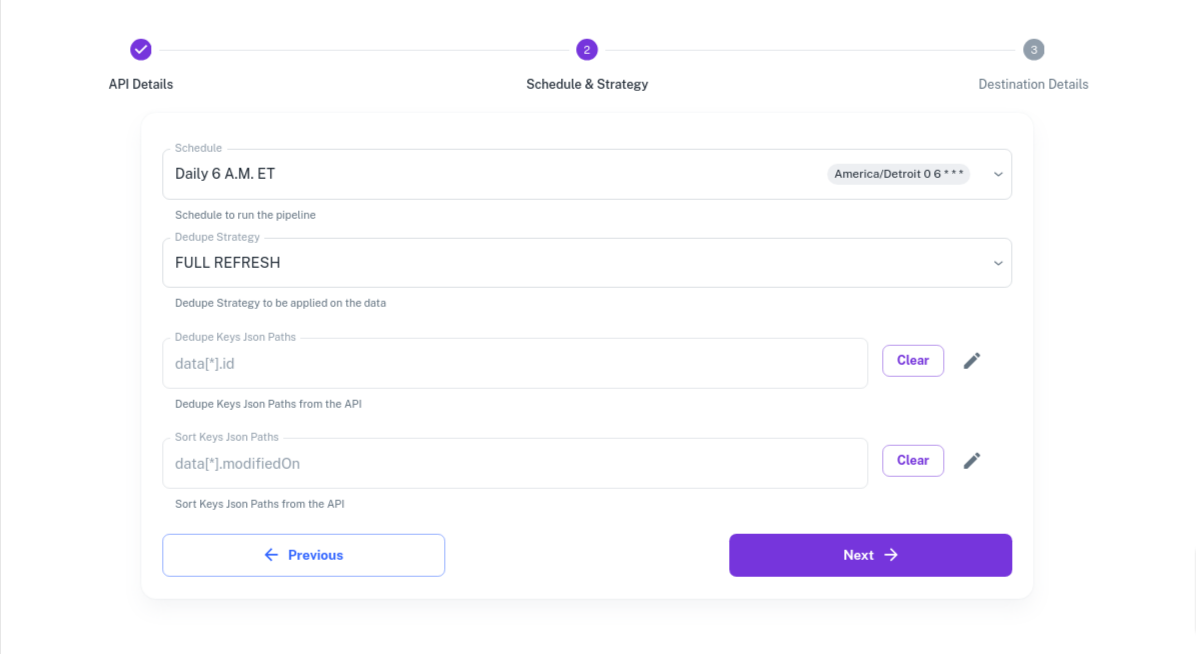
Schedule and Data Load Strategy: Define the pipeline run schedule, and how data is to be written to the Azure Blob and SQL table.
- Select 6 AM Eastern Time or create a new schedule in Settings > Schedules.
- Set the Dedupe Strategy to FULL REFRESH.
- Dedupe Keys Json Paths - Leave it blank or select one the ID fields. Refer to Dedupe and Sort Key documentation
- Sort Keys Json Paths - Leave it blank or select one of the fields. Refer to Dedupe and Sort Key documentation
Destination Details: Specify the Azure Blob and Azure SQL locations where data is to be written.
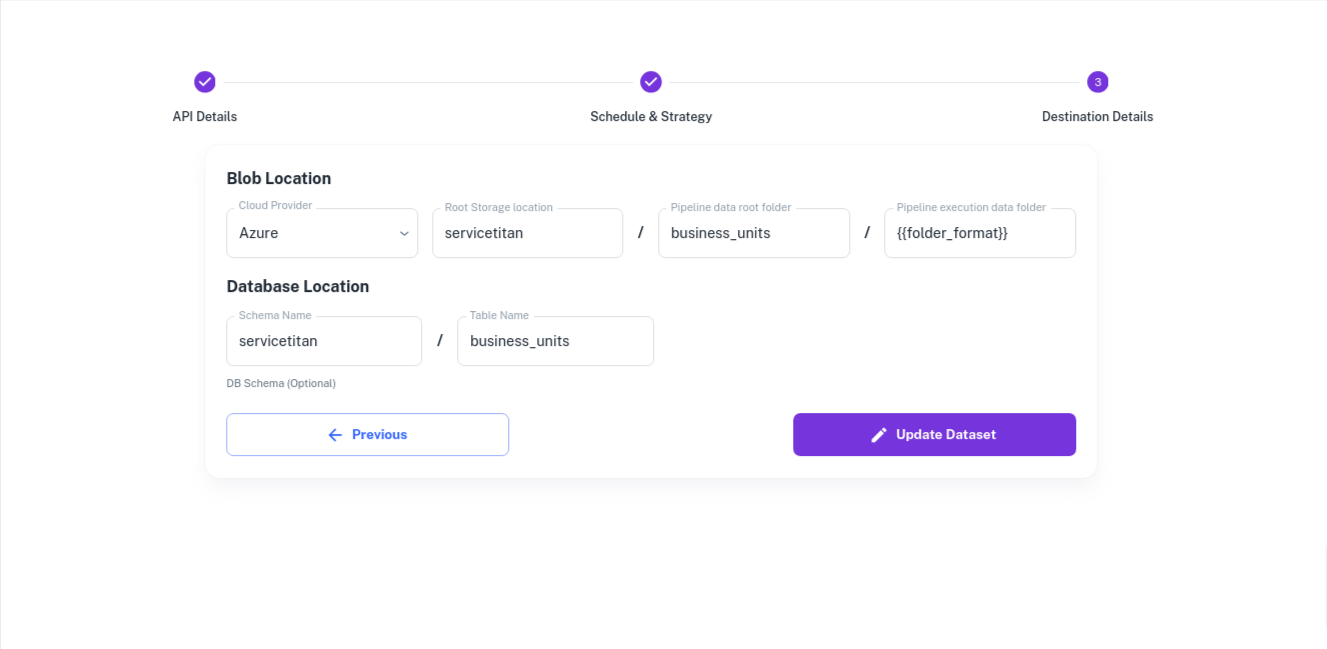
{{folder_format}}refers to the variable we created in the API Details section. A new folder is created for each day's execution using the variable{{folder_format}}and data is written to it.- Final deduped data is available in the 'final' folder.
- Schema changes are tracked under the 'schema' folder.
Sample output in the Azure Blob is as follows:
Save the form and exit the page.
With the above setup, the BusinessUnits pipeline will run on schedule at 6 AM Eastern Time. To run it on demand, go to Integrations > Select Data (for the BusinessUnits pipeline) and click on the Play button under Datasets.
Pipeline Execution
The pipeline executes in the customer's cloud environment. This can be audited from the Azure Container Instances logs.
Pipeline execution status is shown in the dashboard and any failure notifications are sent to the email IDs specified in Settings > Notifications.