How DataStori Works
This page outlines how DataStori runs data pipelines in the customer's cloud in a secure, scalable and reliable manner.
Overview
DataStori orchestrates data pipelines from its cloud hosted in the AWS US East-1 region, but executes them in the customer's cloud. The data source and destination are both in the customer's cloud, ensuring that user data never leaves their environment. The following schematic gives a high level view of DataStori.
Data Flow
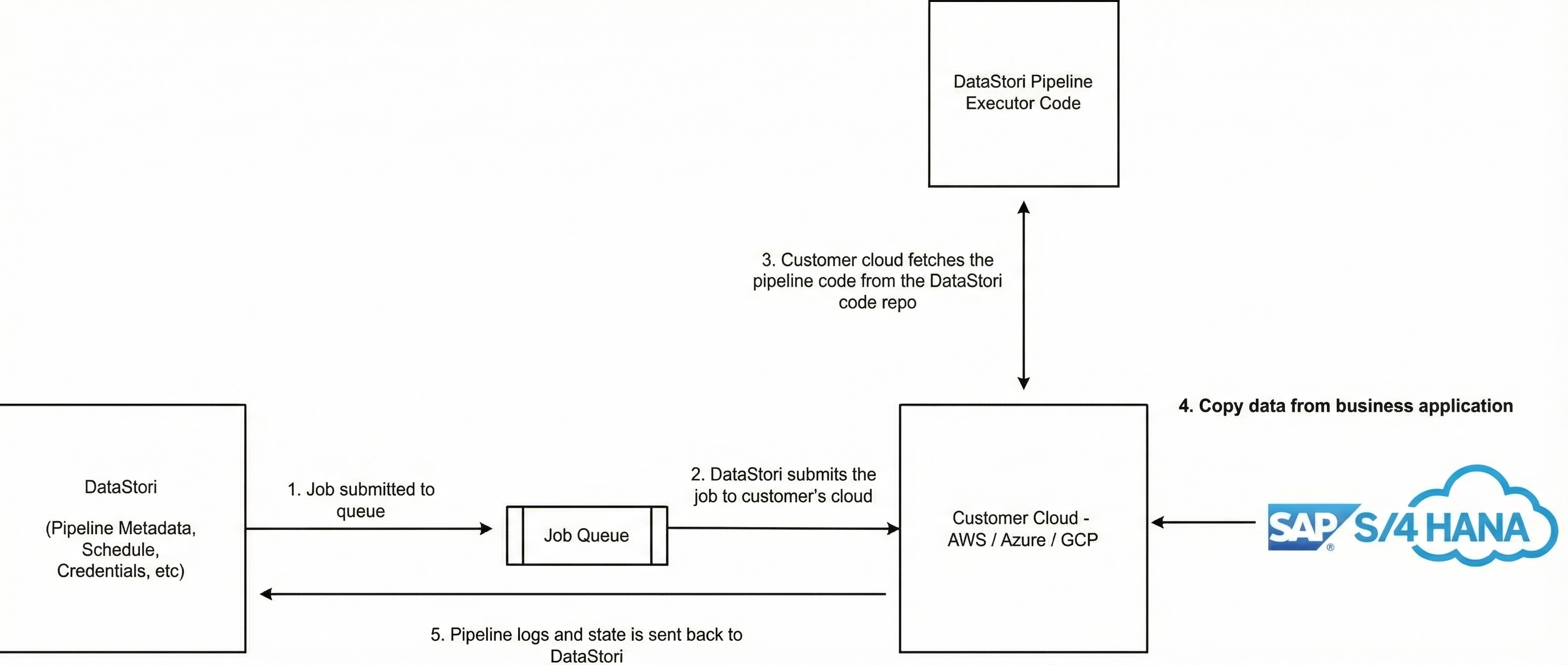
1. Configuration
Configure your data pipeline from https://app.datastori.io and define the following parameters:
- Connect your data sources (databases, APIs, files and others) by providing your credentials.
- Define your destination storage.
- Schedule your pipeline runs.
2. Execution
When a pipeline runs:
- DataStori launches a server in your cloud account.
- The server fetches the code from the DataStori repository.
- The server connects to your source applications using the credentials provided in Step #1.
- Data is extracted according to your configuration.
- Data quality checks are applied to the data.
- Processed data is loaded into your cloud storage and pushed to additional destinations if required.
- The server stops and is shut down.
- Each data pipeline launches its own server, which is shut down upon pipeline completion.
3. Monitoring and Alerts
Through the execution:
- The servers launched in Step #2 share the pipeline state and logs with DataStori. The pipeline state is used to orchestrate the pipeline.
- DataStori supports tracking of pipeline progress in real-time.
- Logs and metrics are available for debugging.
- Notifications alert you to any issues or failures during pipeline execution.
4. Security and Isolation
DataStori is SOC 2 Type 2 compliant and does not have any access to your data. Go to our Trust center for more details. Since DataStori runs your pipelines in your cloud:
- Your data moves directly between your source application and your cloud destination storage.
- Data processing and storage is entirely in your cloud.
- Your data never leaves your environment.
- You can define the access and governance rules on your data.
- Every pipeline runs in an isolated environment (since each pipeline spins up a new server), ensuring that there are no bottlenecks or single points of failure.
- You can revoke DataStori's access to your cloud at any time.
5. Scalability
DataStori is built using serverless architecture, which ensures that:
- Pipelines scale automatically based on data volume.
- No infrastructure provisioning or management is required.
- You pay only for the compute time used during pipeline execution.
- Large datasets are handled without manual intervention.