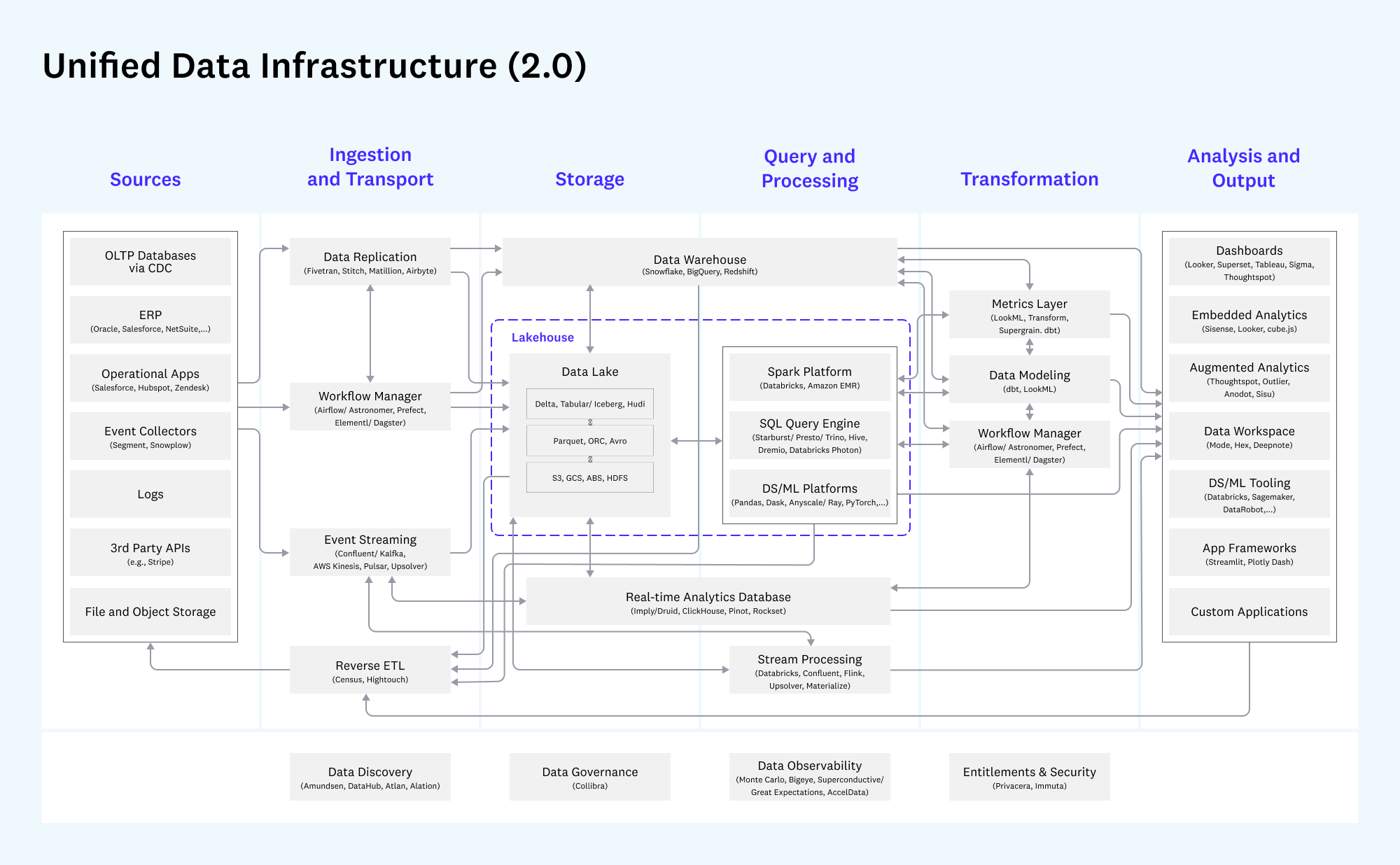
Data organization in DataStori
In DataStori we organize data into a classic three layer strategy. This pattern is now referred as Medallion architecture.
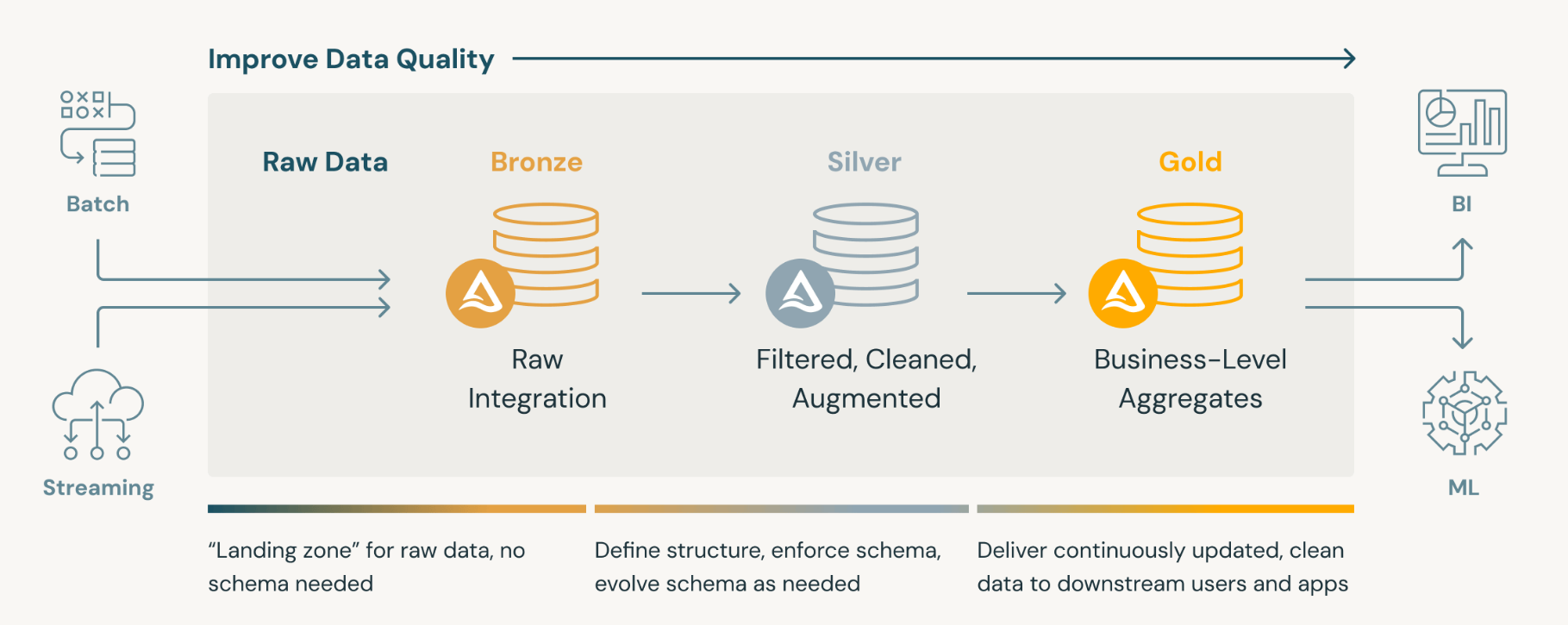
Three layers for data organization:
Bronze layer: Raw data
This is where the raw data lands from APIs, Emails and SFTP servers. The data is stored in the form as it is received from the sources. In this layer the data can be in any format (JSON, XML, CSV, XLSX). The data in this layer should be used with most caution as it can have duplicates, inconsistencies and errors.
The data in this layer can be used for debugging and traceability in case any errors are reported in the downstream layers.
The technical expertise required to handle this layer is high.
Silver layer: Clean data
This is where data is read from the Bronze layer, cleaned, flattened, schema checked, deduped and checked for basic quality. The data in this layer is usually in Parquet or Delta file format. The data is this layer is good for consumption by data analysts and by data analysis tools.
The technical expertise required to handle the data in this layer is moderate.
Gold layer: Business data
The data in this layer is read from Silver layer and transformed as per your business requirements. For e.g. you want to join the data coming from Netsuite and ServiceTitan or if you want to perform a data aggregation. The data format in this layer can be anything that your business requires (Excel, CSV, Parquet).
You can have business rules in this layer to test the data for accuracy of KPIs and Metrics. The data in this layer is most suited for your reporting tools or reporting requirements.
The technical expertise required to handle the data in this layer is moderate.
Databases and SQL Query Engines
The data for the above three layers is created and stored in cloud storage (AWS S3, Azure Blob or Google Cloud storage).
With the data available in the Silver and Gold layers for consumption, what is the requirement of having a DB? Please note that the data in cloud storage is kept in form of files and you still need a query engine to run analysis on the data. This is why the data from Silver or Gold layer needs to either pushed to a database or use other tools that can offer you a querying mechanism on top of Gold or Silver layers directly.
E.g. of databases - Snowflake, Azure SQL, Postgres. E.g. of tools operating directly on your data in storage - SQL analytics endpoint in Microsoft Fabric endpoint (internally it too is a warehouse!)
Other ways of organizing the data
Not only Medallion but there are other data organization architectures too. For e.g. Lambda, Kappa, Data Marts, Data Mesh and your choice of architecture is dictated by your use case.
For DataStori we find Medallion architecture serving the use case of our customers the best. Medallion in addition is easier to understand, defines the ownership of each of the layers cleanly and makes it easier to establish lineage and is generic enough to support a broad set of use cases.